 Center for Applied Research on Supply Chain Services at Fraunhofer IIS
Center for Applied Research on Supply Chain Services at Fraunhofer IISData-Centric AI (DCAI) - Efficient data processing to increase AI model quality
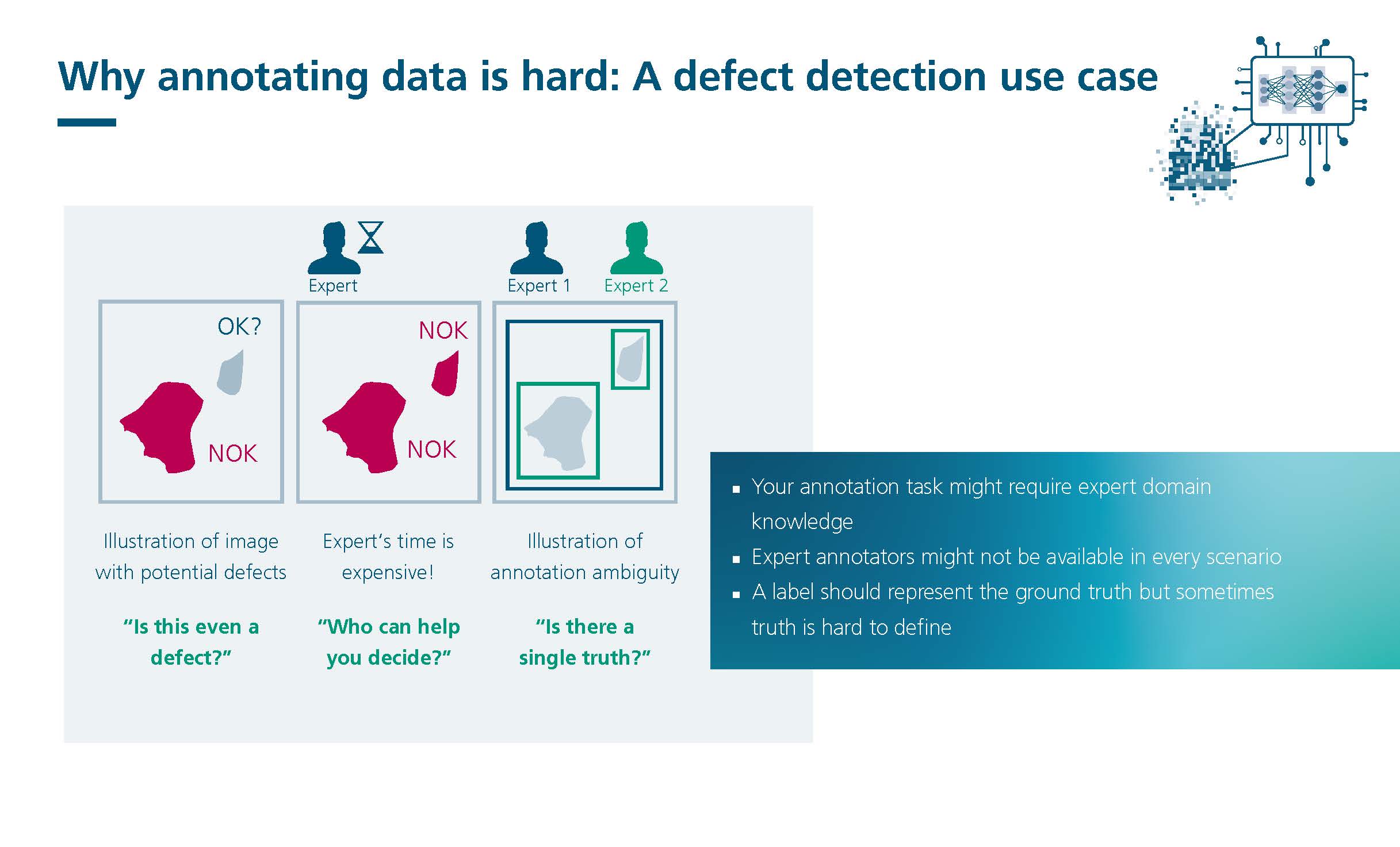
Data quality is critical to the performance of AI models. Improving data quality and simplifying model architecture can increase the quality of AI models.
The process of data annotation, validation and cleaning often requires significant time and resources, and is also prone to errors. Data-Centric AI (DCAI) provides a solution to automate these tasks, reduce the workload and increase quality. This saves valuable time and resources that can instead be used for model development and optimisation.
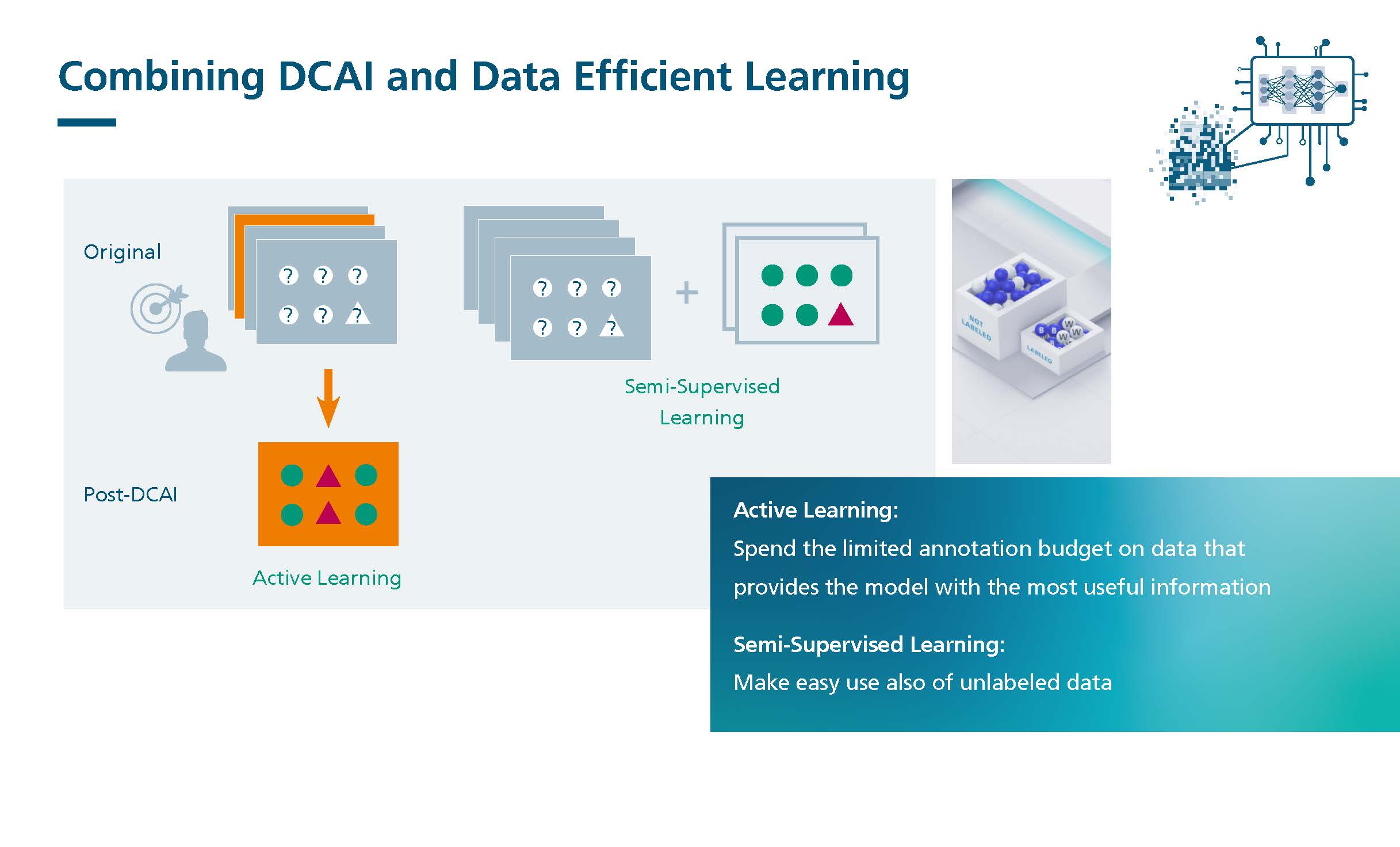
DCAI can also be combined with data-efficient learning, e.g. by using semi-supervised or unsupervised model training. The goal here is to achieve optimal model performance with minimal use of annotated data points. By allowing the model to learn efficiently from the available data and labels and to autonomously recognise patterns in the unlabelled data, the reliance on expensive and time-consuming manual annotation processes can be reduced.
The advantages of DCAI are multiple
Automation of tasks: DCAI automates data annotation, validation and cleaning, which significantly reduces the manual workload. This allows more time to be spent on developing and optimising the AI model.
Time and resource savings: By automating data processing, DCAI saves valuable time and resources. This leads to accelerated model development and more efficient use of resources.
Increasing model quality: By improving data quality and simplifying model architecture, DCAI can increase the quality of AI models. This leads to more accurate and reliable predictions.
Data-efficient learning: By combining DCAI with data-efficient learning, the model can be effectively trained with a limited number of annotated data points. This reduces the need for expensive annotation processes.
