Division Supply Chain Services at Fraunhofer IIS
Division Supply Chain Services at Fraunhofer IISWhy use AI for non-destructive quality assurance in a production context?
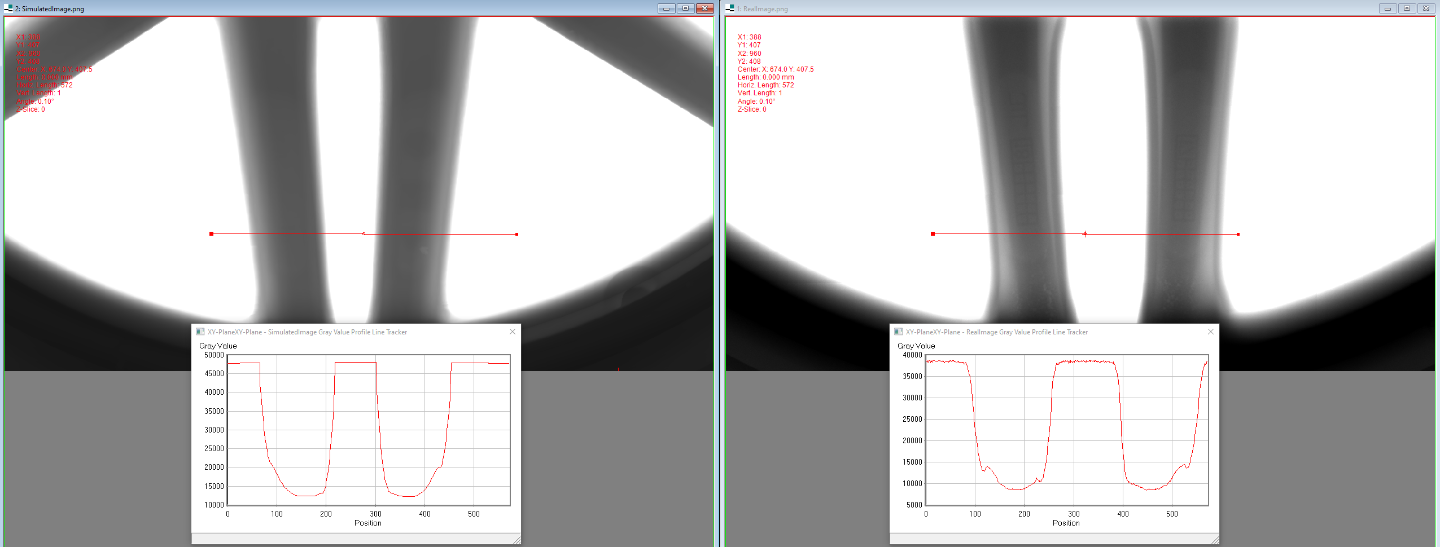
In this project, we focus on the non-destructive detection of defects in lightweight metal castings, specifically automobile tire rims. The common automated quality assurance systems for such components use X-ray images and algorithms based on classical image processing methods. Although these methods are generally effective in detecting many relevant defects, their implementation requires time and specialized personnel for setup, especially for new components. AI-based methods offer the potential for more flexible solutions, particularly in situations where skilled experts are scarce or frequent recalibrations are necessary due to product variety. Our joint project with the Development Center X-ray Technology at Fraunhofer IIS (EZRT) aims to develop an AI capable of accurately detecting defects in X-ray images of castings.