Durch Digitalisierung und die stetige Entwicklung in der Erforschung von Künstlicher Intelligenz (KI), insbesondere im Bereich Machine Learning (ML), profitieren derzeit viele Unternehmen, indem sie neue datengetriebene Geschäftsmodelle entwickeln oder Prozesskosten (z. B. in der Fertigung) senken können. Ein wichtiger Baustein für diese KI-Entwicklung ist das Vorhandensein einer großen Menge von qualitativ hochwertigen Daten.
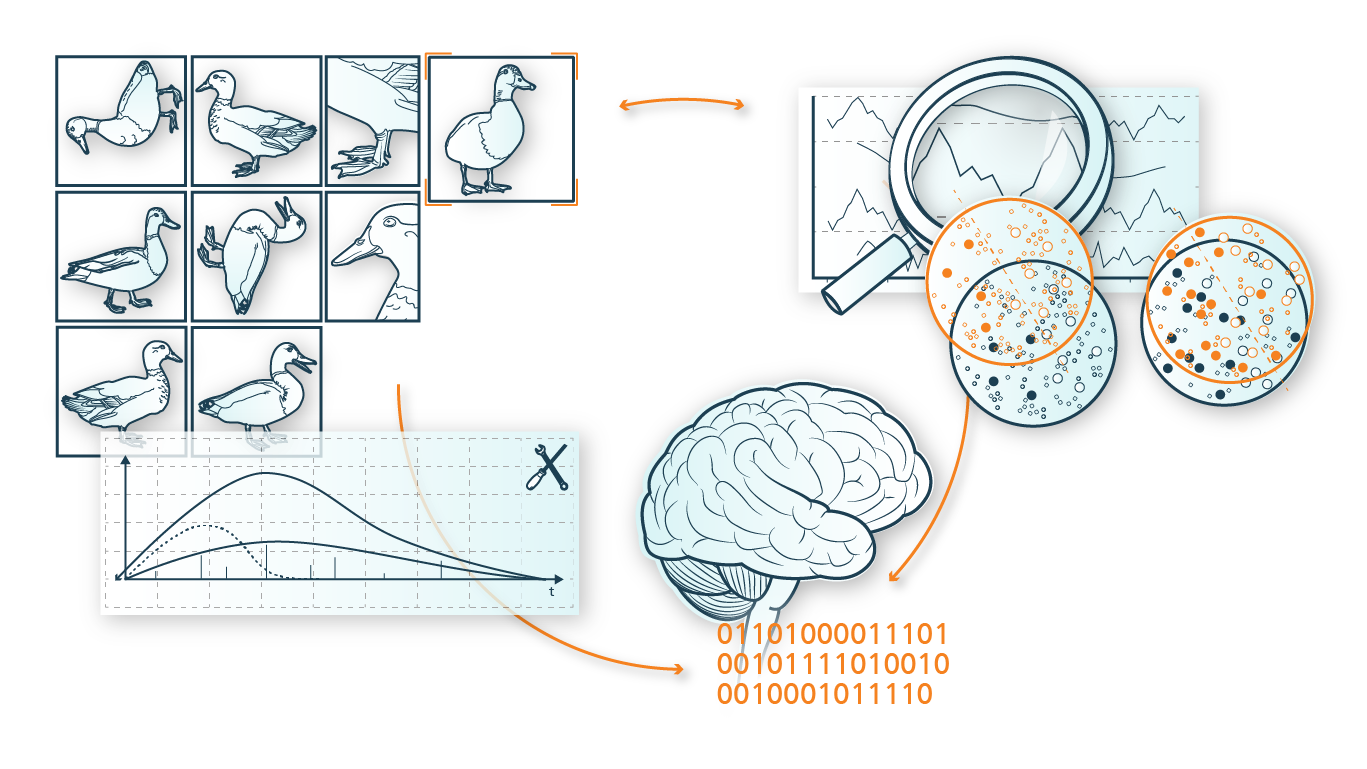
Doch nicht immer sind die Daten in einer ausreichenden Menge vorhanden, vollständig, fehlerfrei oder aktuell, sodass sie für ML-Anwendungen nicht wirklich sinnvoll genutzt werden können. Durch Methoden der Datenerweiterung (Data Augmentation – kurz: DA) ist es möglich, die Datenqualität und -quantität signifikant zu verbessern. Dadurch können ML Modelle in manchen Anwendungsfällen erstmalig eingesetzt oder die Ergebnisse bestehender ML Modelle optimiert werden.
Few Data Learning kommt in Anwendungsbereichen zum Einsatz, in denen eine sehr kleine Datenbasis vorliegt: beispielsweise im Bereich der Bilderkennung, vor allem in der Medizintechnik zur Diagnose von Gewebeanomalien, für Computer Vision Anwendungen in der Bild- und Videoproduktion, oder für Prognose- und Optimierungsanwendungen in der Produktion und Logistik.
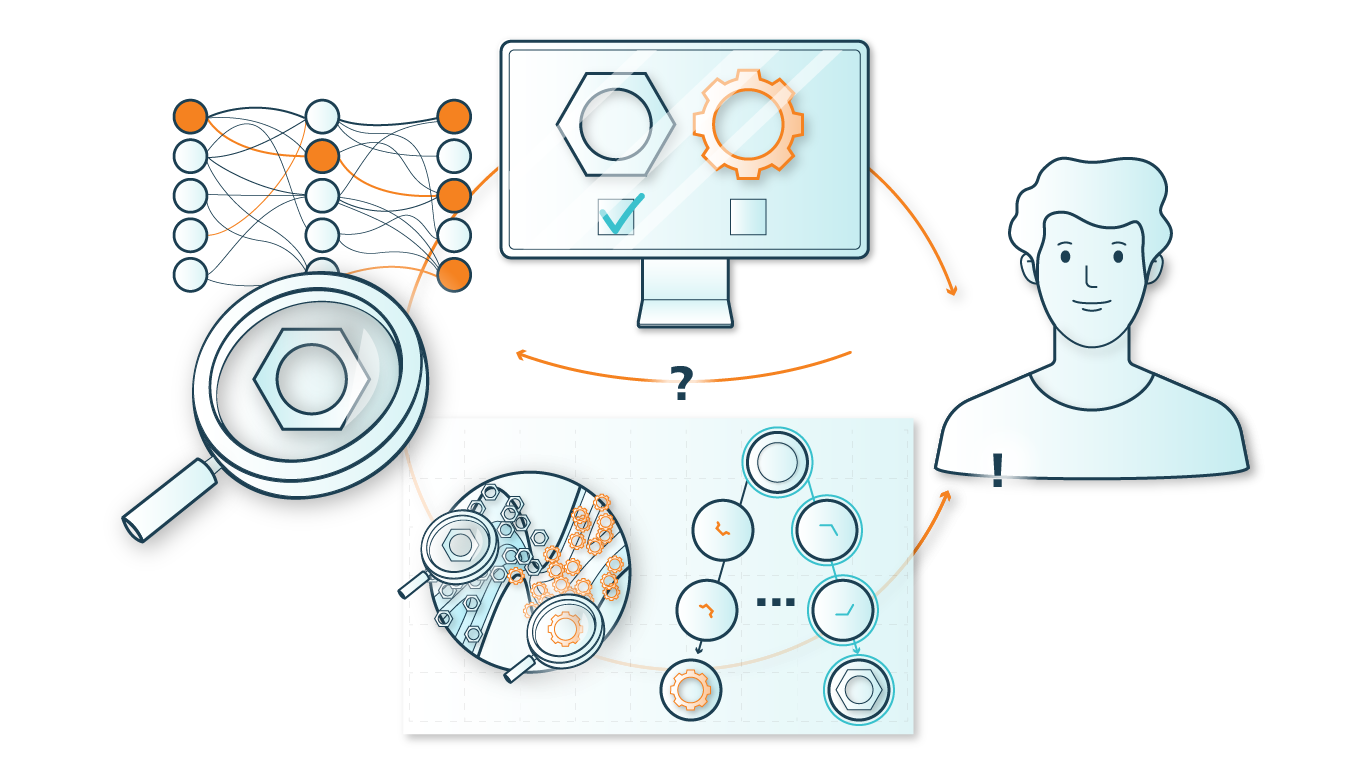
Bestehende Few Data Learning Methoden wurden für jeweils sehr spezifische Datenprobleme entwickelt und verfolgen unterschiedliche Zielsetzungen. Daher ist die Herausforderung in Forschung und Anwendung, für einen konkreten Anwendungsfall die richtigen Few Data Learning Verfahren auszuwählen, miteinander zu kombinieren und weiterzuentwickeln.
Innerhalb des ADA Lovelace Centers ist die Arbeit der Kompetenzsäule Few Data Learning eng verknüpft mit der Säule Few Labels Learning, in welcher die Annotation großer Datensätze im Fokus steht. Denn in der Praxis treten beide Probleme häufig zusammen auf: Wenn Daten fehlen, fehlerhaft sind oder nicht in ausreichender Menge vorhanden sind, fehlen häufig auch die dazugehörigen Annotationen. Daher werden Verfahren aus den beiden Kompetenzsäulen »Few Data Learning« und »Few Labels Learning« oft miteinander kombiniert.
 Bereich Supply Chain Services
Bereich Supply Chain Services