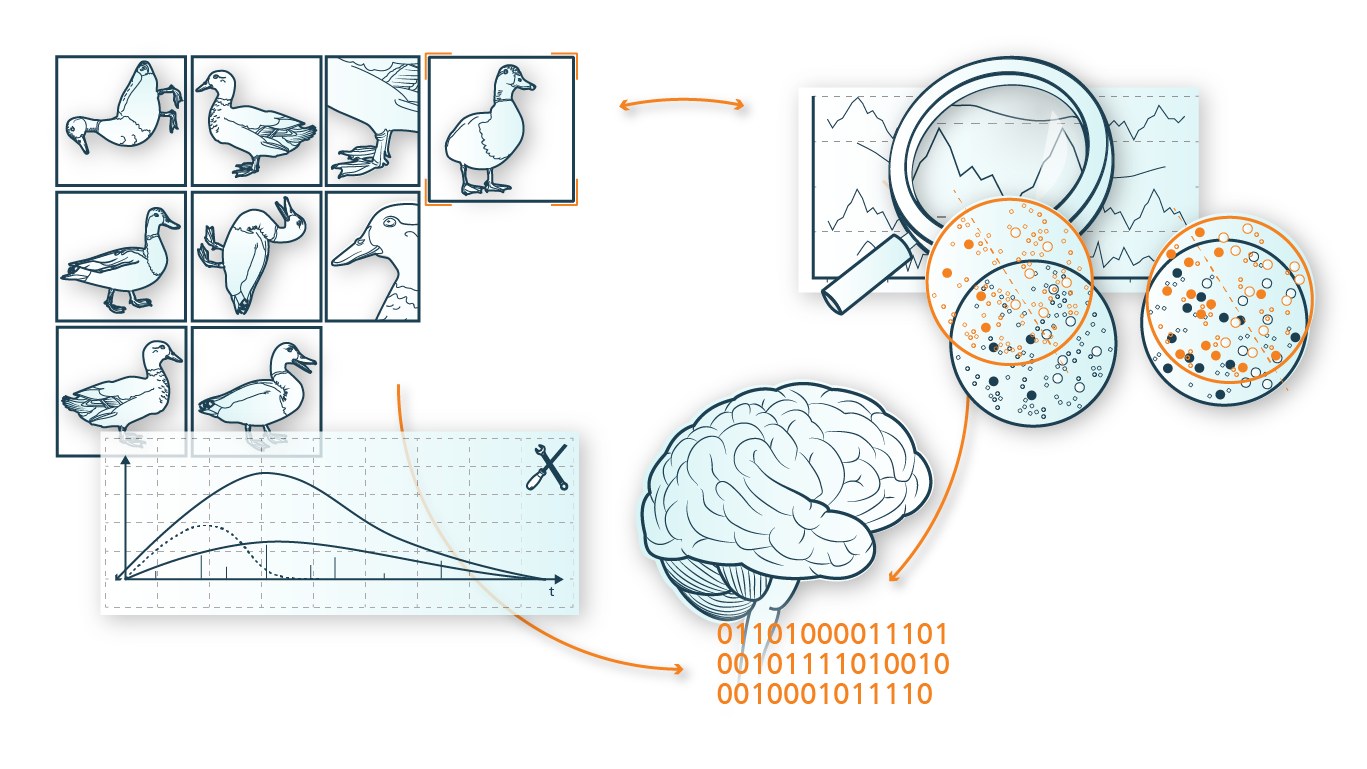
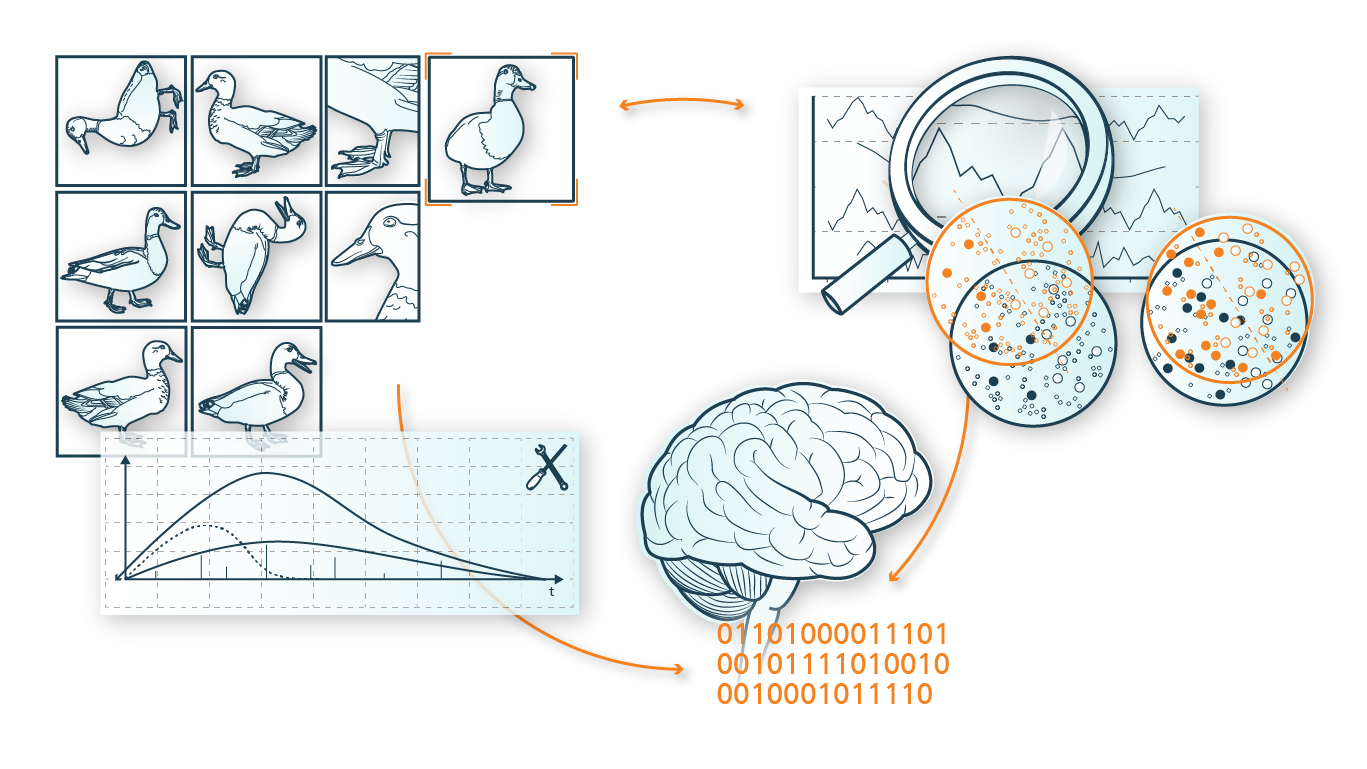
If a time series (here demand in units for a product) is to be extended with a few data points for ML modeling, a search can be made for similar time series that already exist. Subsequently, these data points are taken over directly to extend the short time series. The search for similar data is done, for example, using clustering methods.
If such a direct assignment to similar time series is not possible, difficult or not desired, a synthetic data series can be generated from several available time series instead, which represents the information of the many data series. In this case, redundancies in a high-dimensional data set are used in order to generate a low-dimensional representation of the entire data set.
In some applications, there may even be no data at all for analysis. In this case, simulation models can be used to generate completely synthetic data. For example in production: If an existing production is to be converted to a completely new product, there are no empirical values or data for this yet. In this case, a simulation environment can be created based on the existing data and process modeling, which simulates data for the new products and then analyzes them using ML models. It is particularly important, but also difficult, to simulate data that is as realistic as possible, which does not overestimate or underestimate certain characteristics (e.g. production errors or machine downtimes), so that the ML model can also deliver good results with real data during operation.
 Division Supply Chain Services at Fraunhofer IIS
Division Supply Chain Services at Fraunhofer IIS