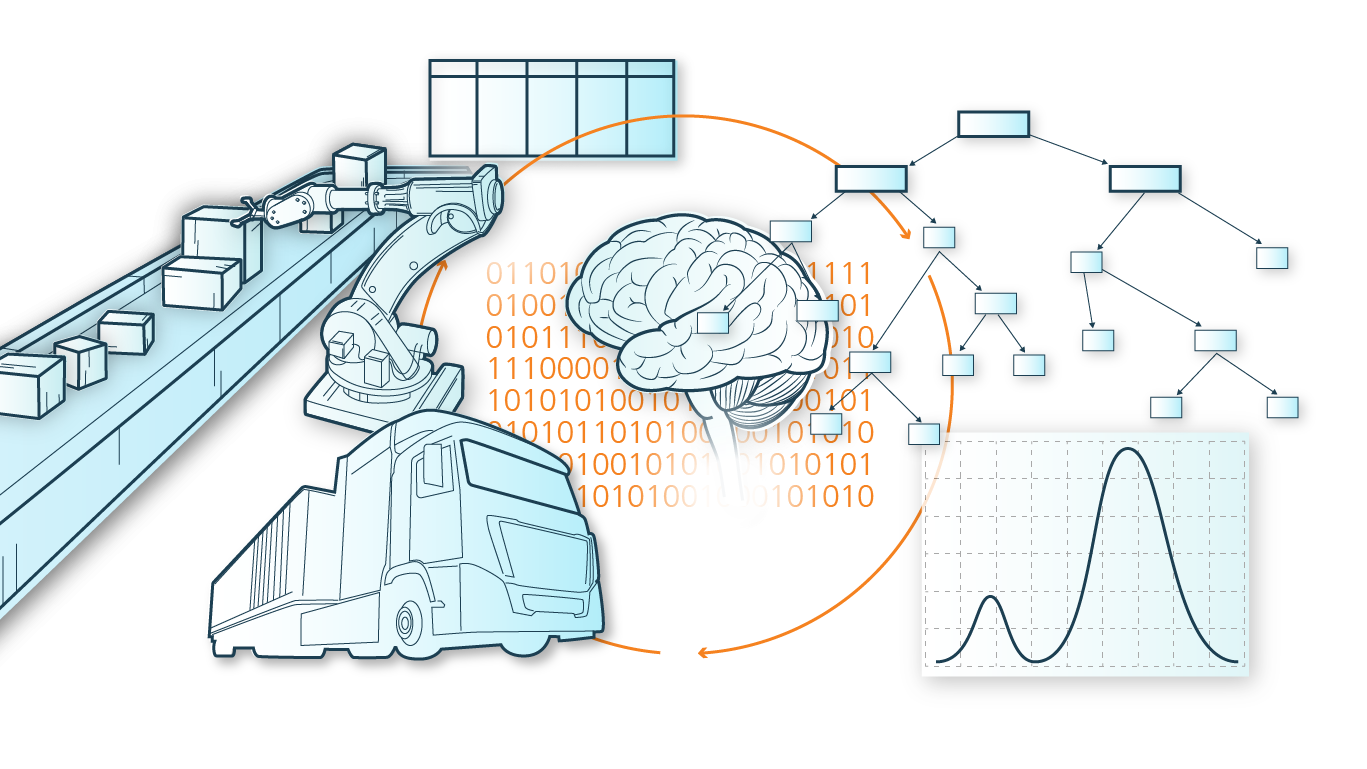
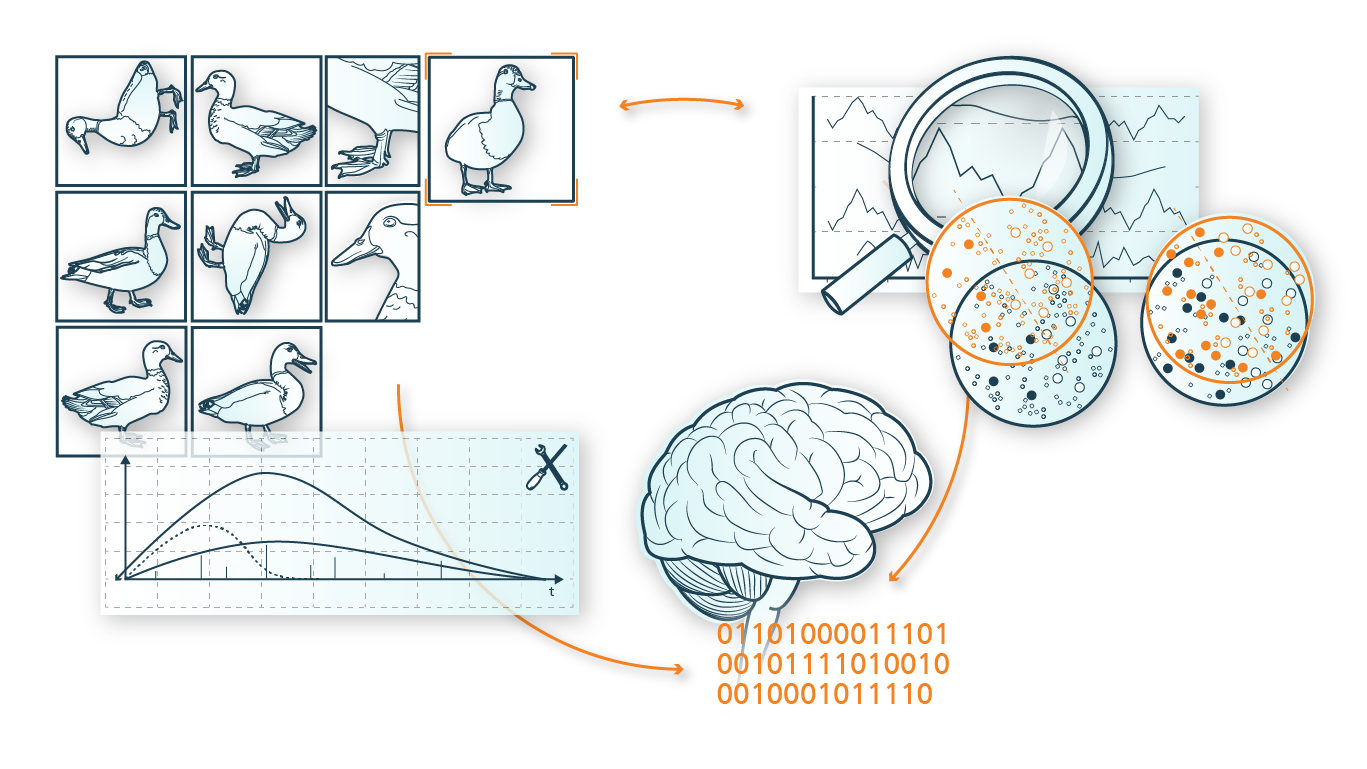
Durch Process Mining werden für Machine Learning nutzbare Daten generiert
Ein erster notwendiger Schritt für die Generierung von Machine Learning Modellen im Prozessumfeld liegt in der Extraktion relevanter Prozessinformationen aus den verfügbaren Daten. Hierfür werden Methoden des Process Mining für die datengetriebene Prozessanalyse und -modellierung genutzt. Die dadurch gewonnenen Informationen und Erkenntnisse müssen anschließend sinnvoll als Eingangsgrößen für Machine Learning Modelle genutzt werden, um mithilfe dieser Modelle die Zusammenhänge zwischen Prozessschritten untereinander und den aufgezeichneten weiteren Prozessparametern und -variablen aufzudecken.
Das übergeordnete Ziel liegt darin, Verfahren zu erforschen, die idealerweise direkt interpretierbare Analysen und Prognosen erzeugen, während sie in der Lage sind eine hohe Komplexität der zu integrierenden Eingangsgrößen und Prozessinformationen zu verarbeiten. Hier liegt der Fokus neben der Nutzung von White-Box-Modellen ebenso auf der verständlichen Kommunikation von Prognosen aus Black-Box-Modellen wie beispielsweise Deep Neural Networks. Ein großer Anteil der Forschung kommt dabei zusätzlich der sinnvollen und kompakten Formalisierung der aus den Prozessdaten extrahierten Informationen zu.
Von den Prozessdaten über Machine Learning zu antizipierenden Unterstützungssystemen
An der Basis des Forschungsfeldes der Prozessanalyse stehen Daten in spezieller Form, sog. Event Logs. Diese unterscheiden sich von üblichen Datenstrukturen wie bspw. Querschnitts- oder Zeitreihendaten dadurch, dass in der Regel zeitlich unregelmäßig verteilte Datenpunkte in Form ausgeführter Aktivitäten vorliegen. Dies erschwert die Anwendung klassischer Analyse- und Prognosealgorithmen, bietet aber auf der anderen Seite die Chance, Methoden wie Process Mining zur Extraktion von datenseitig verfügbarem Prozesswissen zu nutzen.
Dieses Prozesswissen beinhaltet klassischerweise Informationen zur Chronologie verschiedener Prozessschritte, zu bestimmten Mustern im (Teil-)Prozessablauf oder auch über die dabei verwendeten Ressourcen wie Equipment oder Personal, welche sich auf zu analysierende Zielgrößen und Kennzahlen des Prozesses auswirken. Die extrahierten Informationen werden im weiteren Verlauf in erklärbare Machine Learning Modelle integriert, um die Verständlichkeit der entwickelten Methode für Nutzende stets zu gewährleisten. Methoden, welche diese Kriterien erfüllen und daher beim prozessbewussten Lernen vermehrt Anwendung finden, sind beispielsweise Bayes’sche Netzwerke, Markov Modelle oder Entscheidungsbäume.
Prozessbewusstes Lernen in der Anwendung
Analysegegenstand im prozessbewussten Lernen können Prozesskennzahlen wie beispielsweise Durchlaufzeiten oder Ausschussquoten und deren Einflussfaktoren von Produktionsprozessen sein. Ebenso können komplette Prozesse und deren Bestandteile („Aktivitäten“) sowie Anomalien in Prozessen oder Engpässe vorhergesagt werden. Auf diese Weise werden Unsicherheiten in Prozessen bspw. für Fahrerassistenzsysteme im Schienenverkehr greifbar gemacht werden. Die datengetriebenen Prognosen und generierten Vorschläge durch ML-Modelle können Nutzenden als Unterstützungssystem für die Prozessplanung und -steuerung dienen.
Analyseframeworks zur automatisierten Integration von Prozesswissen in Prozessprognosemodelle
Die Integration von Prozessinformationen in erklärbare Machine Learning Modelle ist im Allgemeinen mit einem hohen konzeptionellen Aufwand verbunden. Zusätzliche Anstrengungen der Kompetenzsäule beschäftigen sich daher mit der Realisierung einer automatisierten algorithmischen Erzeugung von interpretierbaren Modellen zur Prozessprognose und der dadurch möglichen vorausschauenden Unterstützung von Prozessplanung und -steuerung. Hierfür werden in Kooperation mit der Ludwig-Maximilians-Universität München Verfahren erarbeitet, um automatisiert, kausale Netzwerkstrukturen aus Prozessdaten zu lernen. Verschiedene Disziplinen aus dem Umfeld des Process Mining insb. der datengetriebenen Erstellung von Prozessmodellen (»Process Discovery«) sollen hierfür auf deren Fähigkeit untersucht werden, kausale Beziehungen zwischen Prozessschritten untereinander und zu weiteren Prozessparametern aus den Prozessdaten zu extrahieren. Der Mehrwert eines solchen Verfahrens liegt in einer enormen Reduktion des manuellen Aufwandes zur Überführung von Prozessdaten in verwertbare Analysemodelle unter Erhaltung der Nachvollziehbarkeit und Interpretierbarkeit der Prognosen und modellgenerierten Vorschläge zur Prozessoptimierung.
Ein wichtiger Schritt hin zur Anwendung von Process Mining und Machine Learning ist eine qualitativ und quantitativ ausreichende Basis an Trainingsdaten. Sowohl im Bereich der Verarbeitung von Zeitreihen, Querschnittsdaten oder der Text- und Bildverarbeitung als auch im Bereich sequenzieller Daten zu Prozessen ist es daher wichtig, Methoden zur hochgranularen, vielfältigen und vor allem fehler- und lückenlosen Gewinnung oder Ergänzung von Datenmengen zu erforschen. Diesem Forschungsbereich widmet sich in erster Linie die Kompetenzsäule »Data-Centric AI«. Im Hinblick auf verfügbare Prozess-Event-Logs ist insb. bei weniger digitalisierten Unternehmen ein großer Nachrüst- bzw. Forschungsbedarf ersichtlich. Für bspw. Produktionsprozesse ist es dabei denkbar, die Digitalisierung der Prozesse und damit die Datengewinnung durch cyber-physische Systeme (CPS) und Simulation zu unterstützen. So können auf Basis des erweiterten Event Logs Prozesse datenbasiert analysiert werden.
Die Kompetenz ist fester Bestandteil der Gruppe »Process Intelligence«
Die Kompetenz »Prozessbewusstes Lernen« ist ein fester Bestandteil der Gruppe »Process Intelligence« der Arbeitsgruppe für Supply Chain Services des Fraunhofer IIS. Die Forschenden der Gruppe widmen sich zwei Schwerpunkten, der datengetriebenen Untersuchung von Unternehmensprozessen und Machine Learning Modellen für Prognose und Überwachung von Prozessen.
 Bereich Supply Chain Services
Bereich Supply Chain Services