Bereich Supply Chain Services
Bereich Supply Chain Services
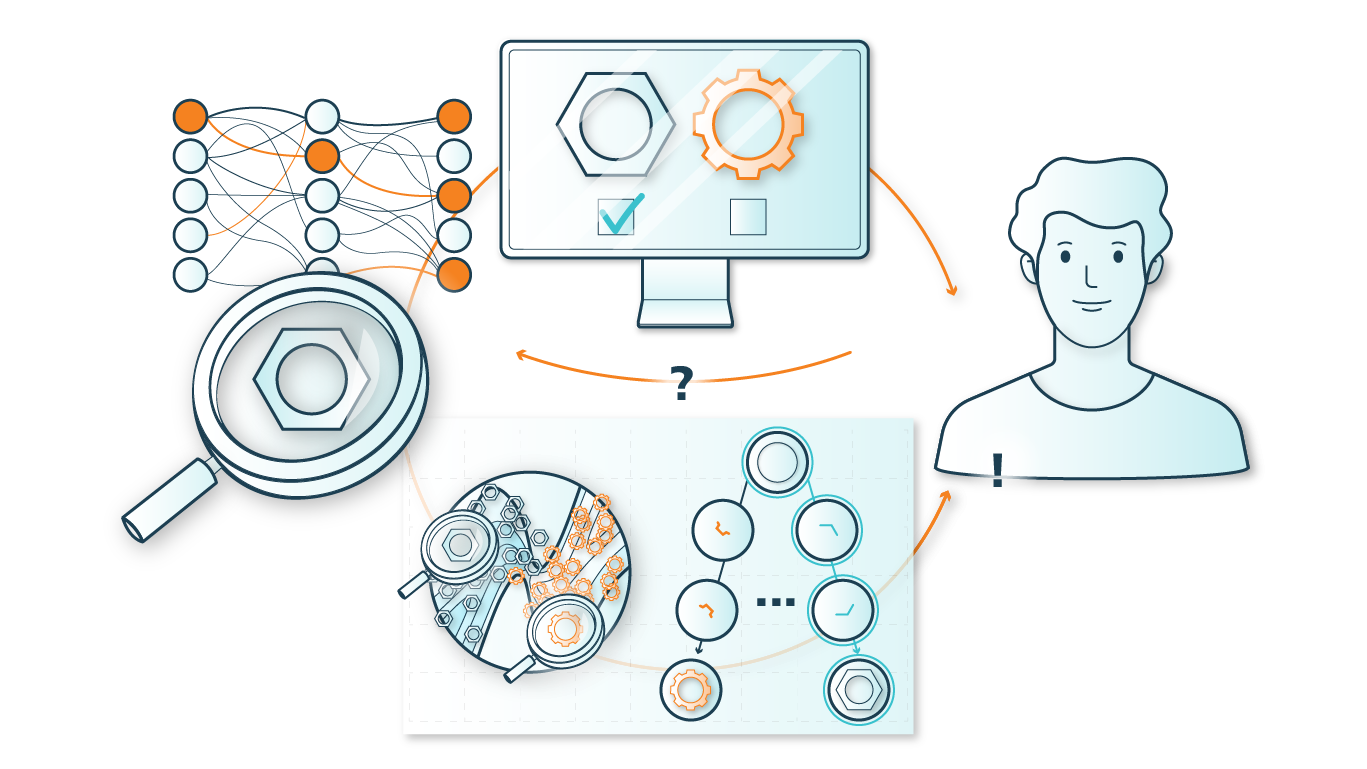
Daten bilden den Rohstoff für alle Anwendungen maschineller Lernverfahren sowie Künstlicher Intelligenz. Nutzenbringende und sinnvolle Erkenntnisse auf Basis dieser Daten lassen sich jedoch nur dann extrahieren, wenn das damit verbundene oder darin enthaltene Wissen, also deren »Semantik«, in geeigneter Weise während oder nach der Entstehung der Daten erfasst, in geeigneter Form, d.h. gleichermaßen in einer von Menschen und Maschinen verständlicher Darstellung beschrieben und mit den eigentlichen Daten in Korrelation gesetzt wird.
Mit Bezug auf diese Anforderungen beschäftigt sich die Kompetenzsäule K8 »Semantik« mit zwei Schwerpunkten:
- Erfassung von Wissen: Der erste Schwerpunkt konzentriert sich auf die Frage, wie »Modellwissen« in verschiedenen spezifischen Anwendungsbereichen (wie z.B. Fahrerunterstützung, Selbstlokalisation, Digitale Pathologie oder Segmentierung von XXL-Tomographie Daten) mit den dafür genutzten und benötigten Messdaten (z.B. Vitaldaten und Emotionen von Personen im Fahrzeug, Lokalisationsparameter, Mikroskopiedaten von histologischem Gewebe, XXL-Tomographiedaten) erfasst und gemeinsam beschrieben werden kann.
- Der zweite Schwerpunkt beschäftigt sich mit der Herausforderung, die erfassten Informationen bzw. Semantiken mit den zugehörigen Messdaten (s.o.) derart zu verknüpfen, dass diese mittels methodischer Ansätze aus den Bereichen Datenanalyse, Maschinellem Lernen und Künstlichen Intelligenz verfügbar gemacht und für verschiedene Anwendungen nutzbar gemacht werden können.