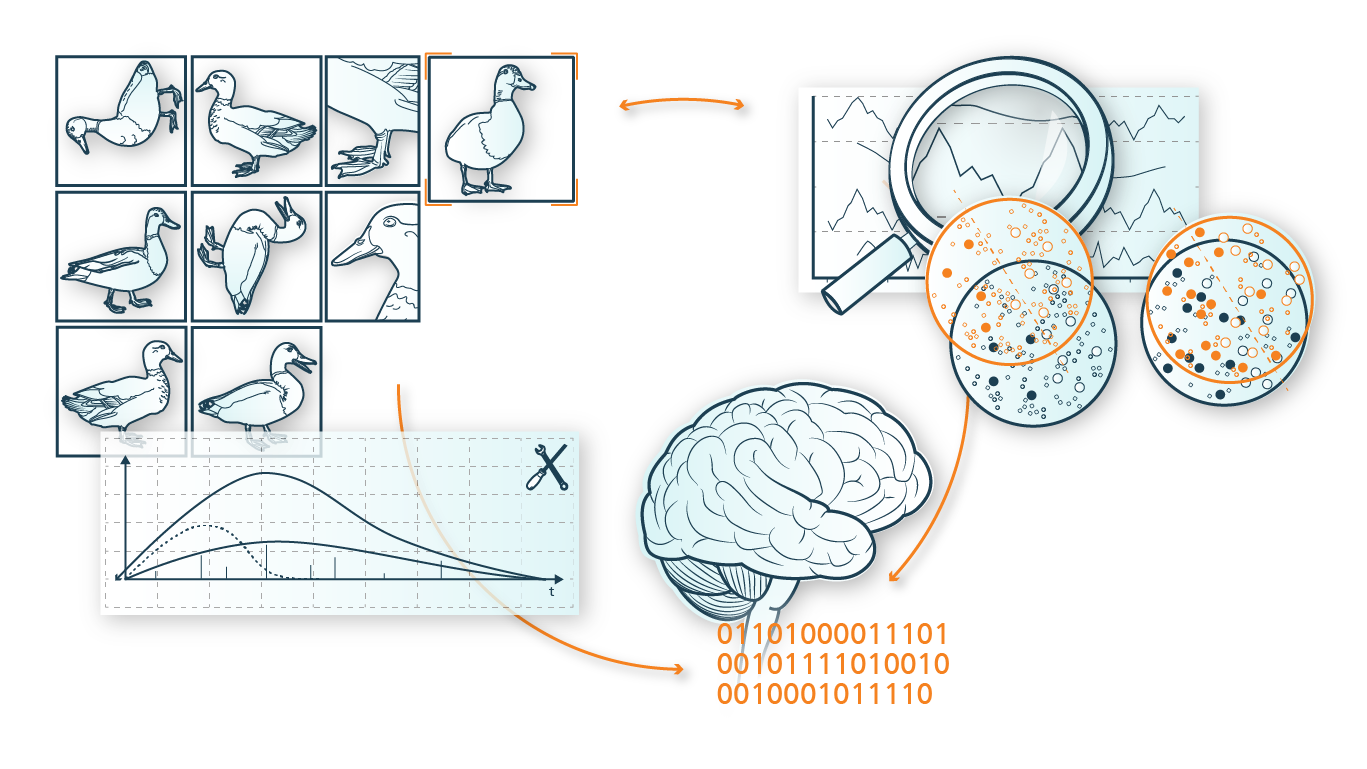
AutoML ist eine der Kernkompetenzen der im Rahmen des ADA Lovelace Centers ins Leben gerufenen Projektgruppe am Standort München, die bereits einige Industrieprojekte durchführen konnte, die sich speziell mit dem Thema AutoML beschäftigten. Oftmals geht es hierbei darum, die Brücke zwischen dem sehr abstrakten Forschungsfeld »AutoML« und einer Anwendung im industriellen Kontext, die am Ende Mehrwert generieren muss, zu schlagen. Es handelts ich hierbei um den klassischen Fall von »Realität passt nicht zur Forschung«. Für Herausforderungen wie unbekannte Kosten bei Klassifizierung, multimodale Daten, imbalancierte Datensätze oder AutoML für Sensordaten können neue Ansätze mit speziell auf die Anwendung zugeschnittenen AutoML Systemen helfen.
Der erste Schritt für erfolgreiches AutoML ist generell die Wahl eines geeigneten Suchraums, also die Entscheidung welche Methoden, Modelle etc. getestet werden können. Dieser Suchraum wird anschließend mit Hilfe einer passenden Optimierungsmethode nach einer optimalen ML-Pipeline durchsucht. Modellbasierte Optimierungsverfahren (MBO), allen voran Bayesian Optimization, sind oftmals eine gute Wahl und wurden in vergangenen Projekten, z. B. für das Design eines AutoML Systems für Qualitätssicherung in der industriellen Fertigung, erfolgreich eingesetzt. Eine beliebte Alternative, die mit hierarchischen und komplexen Suchräumen gut umgehen kann und in bestimmten Fällen besser skaliert als MBO, sind Evolutionäre Algorithmen.
AutoML harmoniert außerdem wunderbar mit den weiteren Kompetenzthemen der Projektgruppe: Erklärbares Lernen und Few-Labels Learning. So sind z. B. auch Methoden des Few-Labels Learning konfigurierbar und müssen je nach Anwendung unterschiedlich gewählt werden. Dies kann mit Unterstützung passender AutoML Methoden entsprechend automatisiert werden.
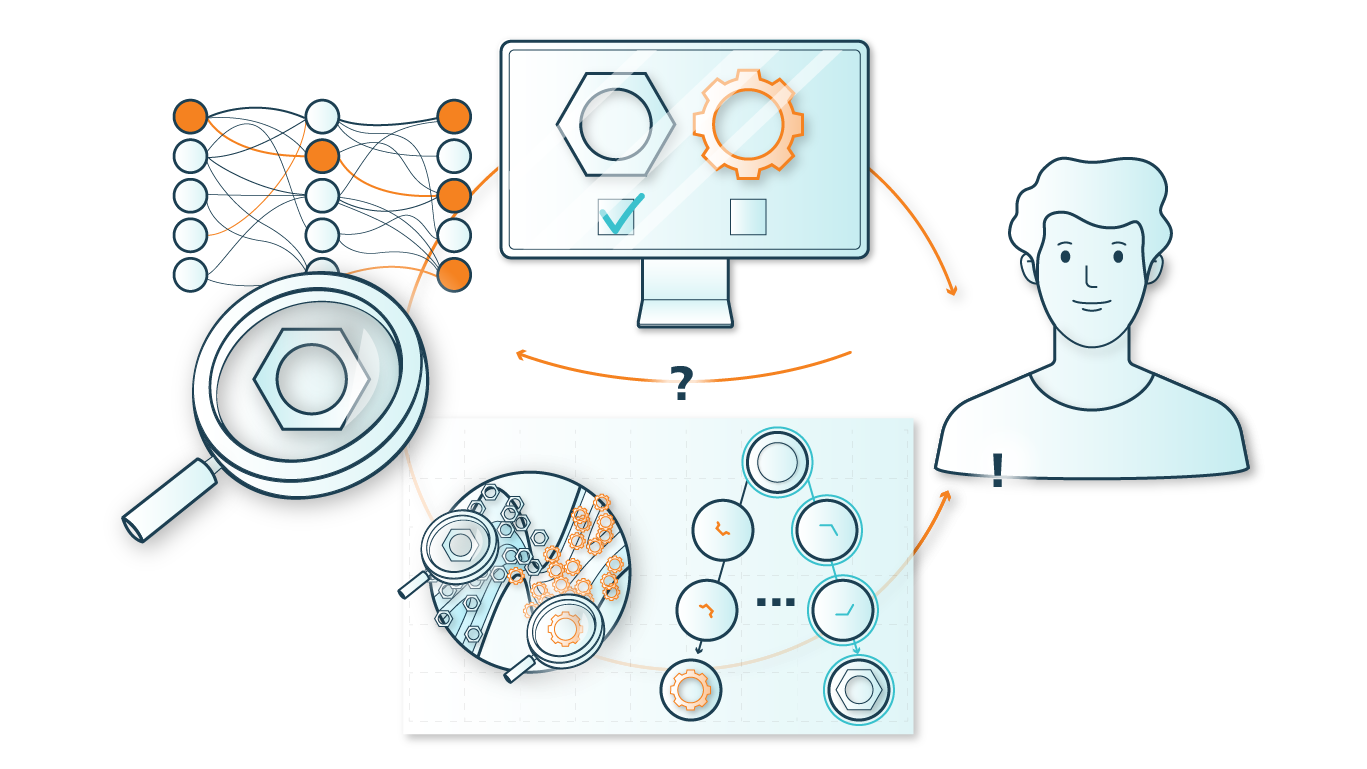
Erklärbarkeit ist indes oft eine Schwachstelle für AutoML Systeme, wenn das optimale Modell nur aufgrund der Performance gewählt wird. Das Resultat von AutoML sind dann oftmals Black-Box Modelle, die zwar sehr gute Ergebnisse liefern, aber nicht länger interpretierbar sind. Mehrdimensionale Optimierung im Rahmen von AutoML kann zwei verschiedene Metriken zur Beurteilung eines Modells – wie z. B. eben Performance und Interpretierbarkeit – in einem Ansatz kombinieren. Ein weiterer Ansatz ist Meta-Modeling, wobei ein Black-Box AutoML System durch ein Meta-Modell erklärbar gemacht wird.
AutoML im Bereich Predictive Maintenance: ALONE – Selbstlernende adaptive logistische Netzwerke
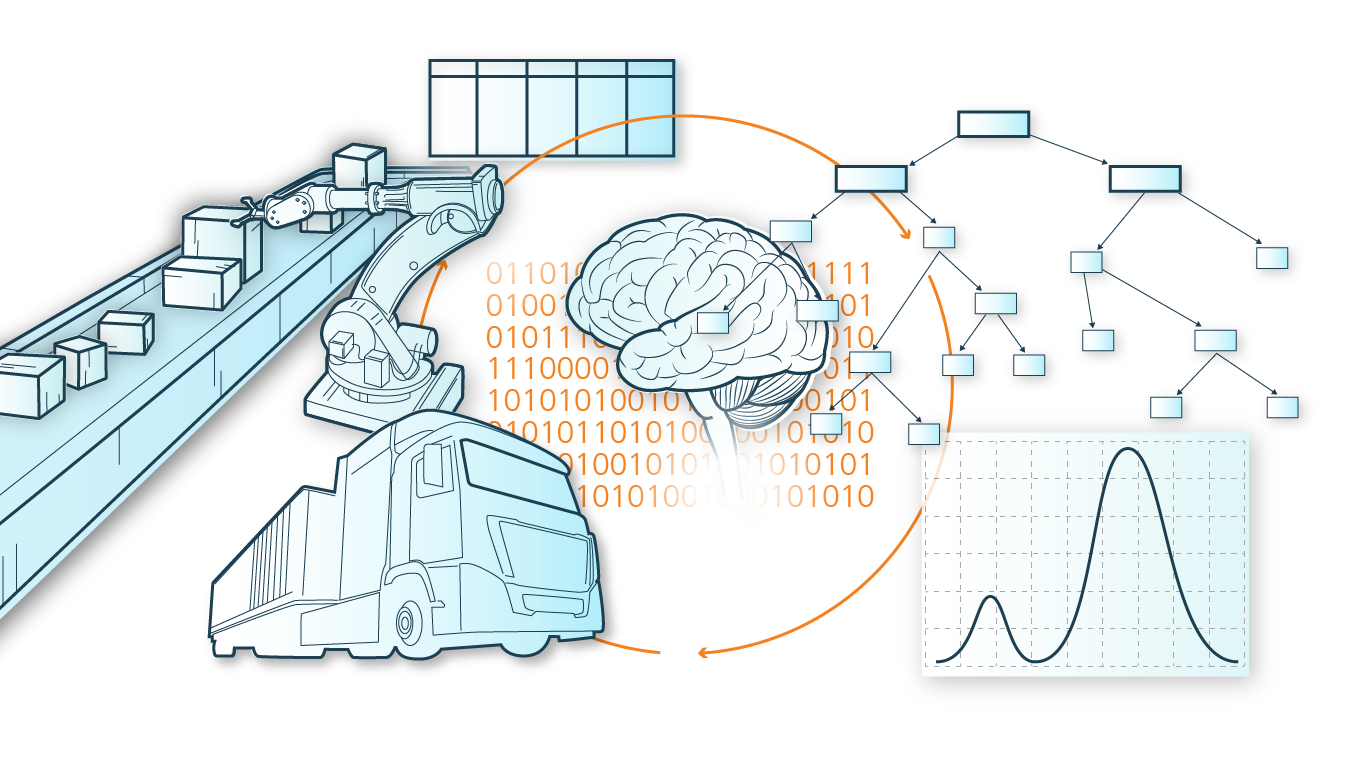
AutoML kann in Situationen verwendet werden, in denen sehr ähnliche Aufgaben mit leicht veränderten Gegebenheiten mehrfach auftreten. Ein Beispiel ist Predictive Maintenance bzw. Machine Health Monitoring. Machine Learning kann die Ausfallwahrscheinlichkeit einer (teuren) Maschine oder die verbleibende Zeit bis zum Ausfall vorhersagen und erlaubt so eine optimierte und planbare Wartung bei minimalen Kosten. Bestimmte ML-Modelle und Preprocessing Methoden sind vielversprechend für diese Art von ML-Aufgaben, jedoch ist es in der Praxis nicht zumutbar für jede Art von Maschine und Umgebung manuell ein optimales ML-Modell auszuwählen. AutoML kann in diesem Fall Abhilfe schaffen und aus allen relevanten Methoden und Modellen für jeden spezifischen Einsatz eine optimale ML-Pipeline generieren.
Mehr Informationen zur Applikation »Selbstlernende adaptive logistische Netzwerke«
AutoML und Meta-Learning: KI-Frameworks für autonome Systeme
Die Applikation »KI-Framework für autonome Systeme« beschäftigt sich stark mit Reinforcement Learning Methoden, deren Performance oft extrem abhängig von bestimmten Hyperparametern ist. Gleichzeitig sind Reinforcement Learning Algorithmen in vielen Fällen extrem teuer. Deswegen wurde in diesem Anwendungsfall effizientes Hyperparameter Tuning für Reinforcement Learning untersucht; außerdem wurde vermehrt an Meta-Learning für dieses Setting geforscht. Meta-Learning versucht, die bereits aus vorherigen Aufgaben gelernten Information sinnvoll für AutoML (bzw. in diesem Fall Hyperparameter Tuning) auf neuen Aufgaben einzusetzen. Je nach Anwendung kann Meta-Learning für die Suche nach einer optimalen Pipeline relevant sein (»Warmstarting«) oder sogar dabei helfen bestehende, fixe Architekturen für neue Aufgaben einzusetzen (»Transfer Learning«). Meta- Learning kann auch bei wiederkehrenden Aufgaben, die sich ähneln – wie z. B. in der Applikation »Selbstlernende adaptive logistische Netzwerke« – ein vielversprechender Ansatz sein.
AutoML als Bestandteil fast jeder Anwendung
Im Rahmen der Zusammenarbeit im ADA Lovelace Center wurden erstmals Fragestellungen aus den Applikationen »Intelligente Leistungselektronik« und »KI-gestützte Zustands- und Störungsdiagnose Funksysteme«, die ebenfalls dem Forschungsfeld Automatisches Lernen zuzuordnen sind, diskutiert. Infolgedessen wurde dort an automatischer Stabilitätsbestimmung von Gleichstromnetzen sowie von Funknetzen durch ML Methoden geforscht.
Hyperparameteroptimierung, Feature Engineering, Modellselektion etc. sind ein Bestandteil fast jeder Anwendung von Machine Learning. Die Kompetenzen der Säule finden daher auch über die das ADA Lovelace Center hinaus in vielen anderen Projekten Anwendung – beispielsweise beim Projekt »Demand Forecast as a Service (dFASSI)«.
AutoML zur Generierung von KI Modellen mit minimalem Energiebedarf (AutoML ASIC)
Die Integration von Energiebedarfs-Prädiktion in multikriterielle AutoML-Verfahren erlaubt uns die automatische Erstellung von KI-Verarbeitungsketten für eingebettete Hardware mit minimalem Energiebedarf. Wie in vielen industriellen ML-Anwendungen, sind für die Anwenderinnen und Anwender zwei widersprüchliche Zielgrößen relevant: Modelle mit kleinem Energiebedarf sind im Vergleich oft weniger komplex und zeigen deswegen eine schwächere Performanz. Entwicklerinnen und Entwickler bekommen in einer multikriteriellen AutoML Lösung deswegen mehrere (pareto-optimale) Lösungskombinationen angeboten, so dass ein optimaler und auf die eigene Hardwarekonfiguration angepasster Trade-Off zwischen Prädiktionsgenauigkeit (Performanz) und späterem Energiebedarf gewählt werden kann. Zum Einsatz kommen hier neben evolutionären Algorithmen und Bayesian Optimization auch Methoden aus dem Bereich Reinforcement Learning (z. B. Augmented Random Search).
Weitere Infos unter https://www.iis.fraunhofer.de/tinyml
 Bereich Supply Chain Services
Bereich Supply Chain Services